上一篇我們學習了第一個Deep Learning的模型CNN,今天我們要探討的是當模型在訓練集(Training Set)或測試集(Testing Set)上無法取得好的結果時,通常可以從模型的結構、學習過程、參數調整等方面來改進模型性能。我們可以針對不同情境提出不同的解決方案,包括激活函數的改進、自適應學習率、提前停止訓練、正則化、以及丟棄層的使用。
進行深度學習(deep learning)或機器學習(machine learning)時,通常可以分為三個主要步驟(深度學習其實就是機器學習的一種):
完成這三個步驟後,我們就會得到一個神經網絡(neural network)。在這個階段,首要的檢查工作是確認該神經網絡在 training set 上的表現是否理想,而非 testing set。若在 training set 上的表現不佳,我們就需要回頭檢查上述三個步驟,並針對其中可能的問題進行調整,然後期待在 training set 上得到良好的結果。
在 deep learning 中,優先檢查 training set 的表現是十分重要的。對於 deep learning,由於模型參數眾多,雖然看似容易 overfitting,但實際上 overfitting 通常不是首先遇到的問題。深度學習模型在 training set 上的表現往往不如 k nearest neighbor 或決策樹那樣容易達到高正確率,因此可能在 training 階段就無法獲得理想的結果,這時便需要回頭檢查模型設計或優化過程,進行必要的改進。
假如你在 training set 上獲得了較好的表現,接下來便可以將該模型應用於 testing set。此時,我們關心的是 testing set 上的表現。如果模型在 training set 表現良好,但在 testing set 表現欠佳,才會稱之為 overfitting。遇到此情況時,可以考慮進一步優化模型,但需注意的是,在優化模型過後,可能會導致 training set 的表現下滑,因此進行修改後要重新檢查 training set 的結果,並根據需要調整模型訓練過程。
最終,如果模型在 training set 和 testing set 上均有良好表現,便可以將其應用於實際場景。重點在於,不要輕易將所有表現不佳的情況都歸因於 overfitting。
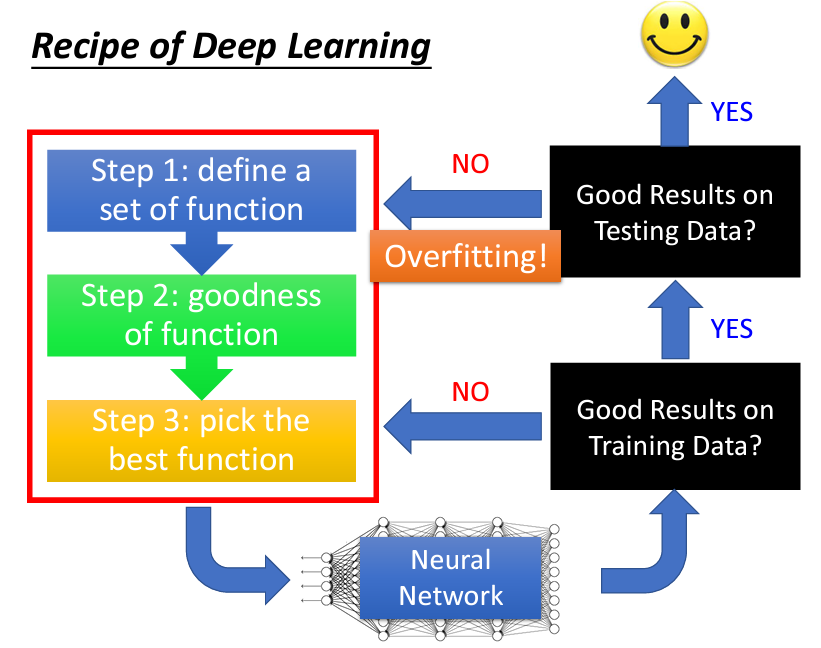
模型在訓練集上表現不佳的原因通常包括:模型結構過於簡單,無法捕捉訓練數據中的特徵(underfitting),或是學習率不合適,導致模型在參數空間中無法找到合適的參數。為了解決這些問題,可以嘗試改進激活函數和學習率的設置。
在選擇或設計網路結構時,activation function 的選擇對訓練結果影響深遠。1980 年代的模型通常使用 sigmoid function,但在現代深度學習中,這種函數並不總是理想的。當網路層數增加時,sigmoid function 的 gradient 可能會變得非常小,尤其在靠近輸入層的地方,這就稱為 Vanishing Gradient 問題。這會使靠近輸入層的參數更新速度變慢,甚至陷入局部極小值,無法有效地訓練網路。
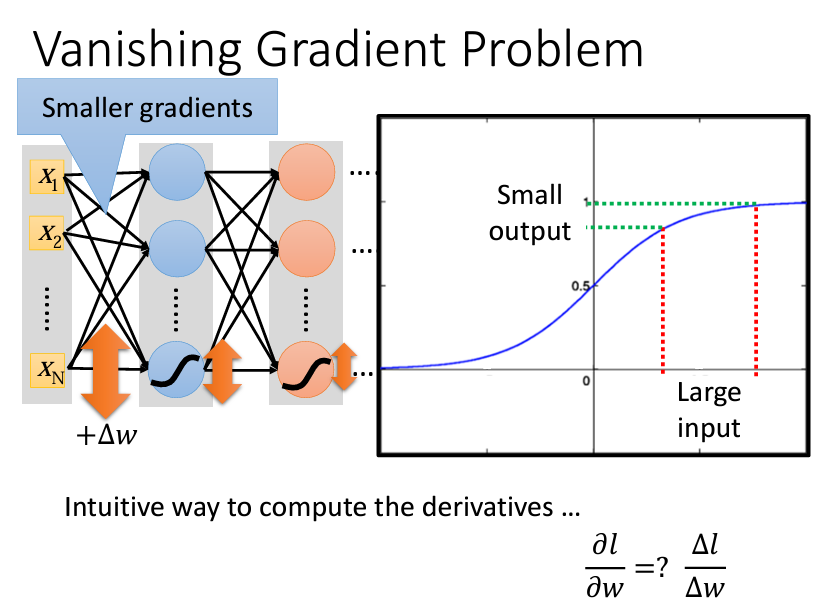
為了解決 Vanishing Gradient 問題,研究者開始尋找新的 activation function。其中,ReLU (Rectified Linear Unit) 成為了當前最常用的激活函數。ReLU 的定義簡單:當輸入值大於 0 時,輸出即為輸入值;當輸入值小於 0 時,輸出為 0。與 sigmoid 相比,ReLU 的計算速度更快,且在大部分情況下能夠避免 gradient 消失的問題,因為它的 gradient 要麼是 0 要麼是 1。

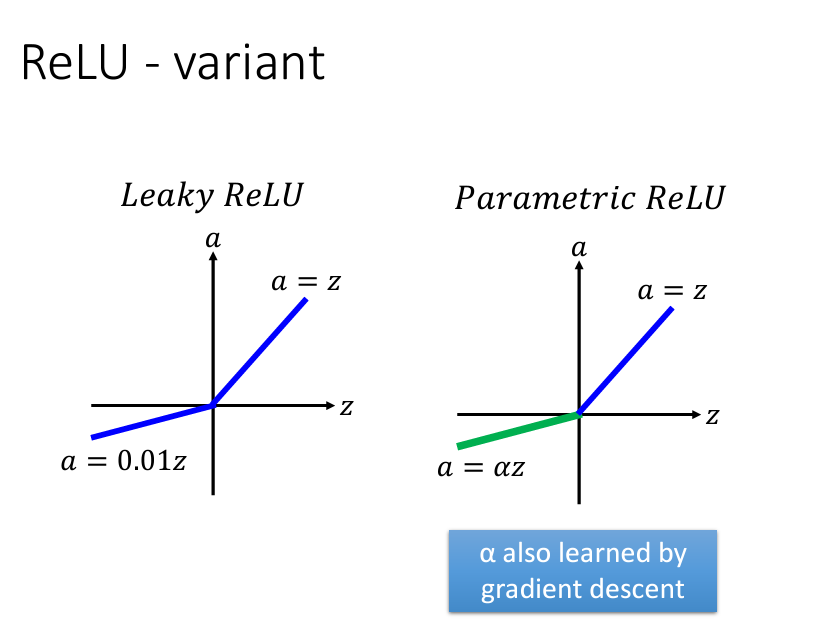
ReLU 虽然优于 sigmoid,但在 input 小於 0 時 gradient 為 0,這可能導致一些神經元 "失活"。因此,出現了 Leaky ReLU,即在輸入值小於 0 時輸出為輸入值的某個比例,例如 0.01。這樣做讓 gradient 保持為一個小的非零值,減少神經元失活的風險。進一步,Parametric ReLU (PReLU) 允許訓練模型自動學習該比例,讓每個神經元的 α 值根據資料調整。
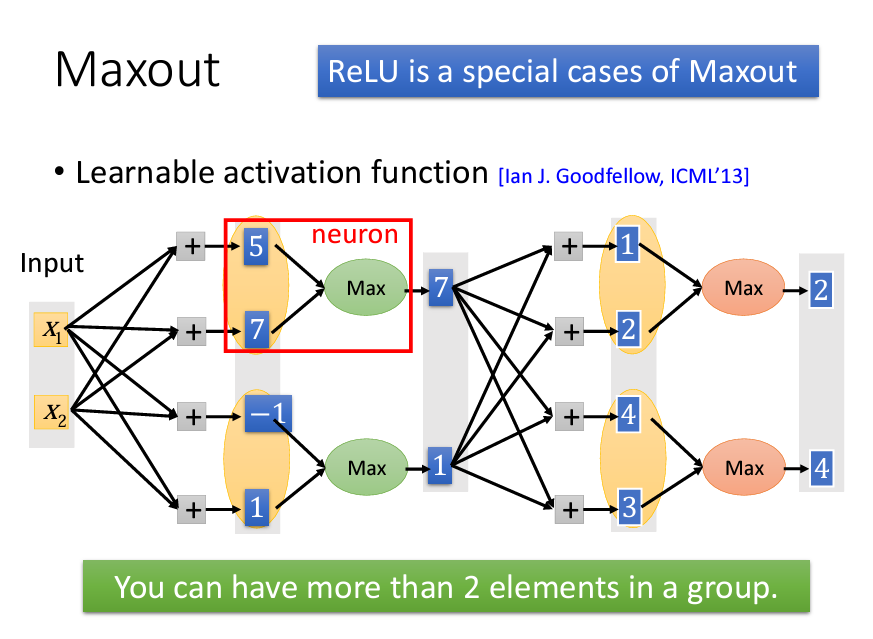
此外,Maxout network 是更進階的 activation function,通過在每一層的輸出中選擇最大值,不需要特定的激活函數。它是一種自適應 activation function,能夠學習出最適合的激活模式,使得 Maxout 在某些應用上具備高度彈性。
激活函數對於深度學習模型的性能有著直接影響。因此,除了上述提到的激活函數,也可以考慮使用一些新的激活函數,如 Leaky ReLU、ELU(Exponential Linear Unit)或 SELU(Scaled Exponential Linear Unit)等。這些激活函數在梯度更新中不會使神經元完全失活,並且能夠提高模型對訓練數據的擬合能力。
學習率是影響模型訓練效果的重要參數。過高的學習率會導致模型無法收斂,而過低的學習率會使模型訓練過程過於緩慢。為了適應不同的學習階段,現代的深度學習優化器通常會使用自適應學習率技術,如 Adam、RMSprop 和 AdaGrad 等。
這些優化器會根據當前梯度的情況,自動調整學習率。例如,Adam 優化器通過結合動量(Momentum)和學習率衰減來適應不同的梯度情境,從而加快收斂速度並提高準確性。在模型訓練過程中,可以選擇這些自適應學習率方法,以提升模型在 Training Set 上的性能。
由於在之前的文章已經有詳細介紹過,因此在本篇不加以復述。
當模型在測試集上表現不佳時,可能是模型過度擬合了訓練數據,即模型對訓練數據的特徵學習過於深入,導致無法很好地泛化到新數據。為了解決這一問題,可以使用提前停止、正則化和丟棄層等技術來減少過擬合。
提前停止是一種監控模型在驗證集(Validation Set)上性能的技術。當模型在驗證集上的損失不再下降時,提前停止可以避免模型過度擬合訓練數據,並在最佳點停止訓練。具體而言,可以在驗證損失連續多個迭代不變或上升時終止訓練,從而提高模型的泛化能力。
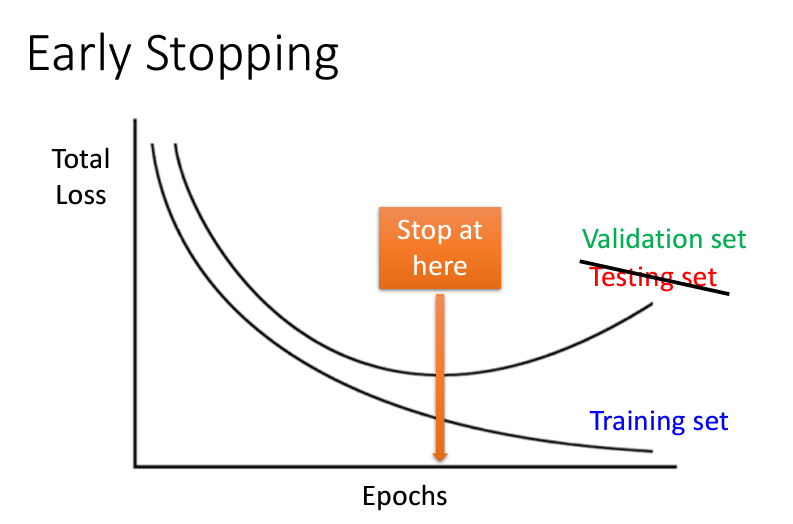
這種方法特別適合於在訓練時間和資源有限的情況下,通過早期停止來提升模型在 Testing Set 上的表現。
正則化是防止模型過擬合的另一有效方法。L1 和 L2 正則化是在損失函數中加入正則化項,使得模型在學習過程中避免學習到過於複雜的參數。L1 正則化會使部分權重變為零,有助於模型的稀疏化,而 L2 正則化則會抑制權重過大,從而減少模型的複雜性。

此外,L2 正則化還常被稱為權重衰減(Weight Decay),在大多數優化器中有內建的支持。選擇適當的正則化係數可以有效降低過擬合的風險,並提高模型在測試集上的性能。

丟棄層(Dropout)是一種在神經網絡訓練過程中隨機丟棄一部分神經元的方法。通過丟棄一定比例的神經元,模型不會過度依賴某些特定的特徵,從而強化模型的泛化能力。典型的 Dropout 比例範圍為 0.2 到 0.5,具體值則根據模型和數據集的需求進行調整。
隨機丟棄 Neurons: 在訓練過程中,每一次參數更新前,對於每個 neuron(甚至包含輸入層的元素)進行隨機抽樣,以決定是否丟棄該 neuron。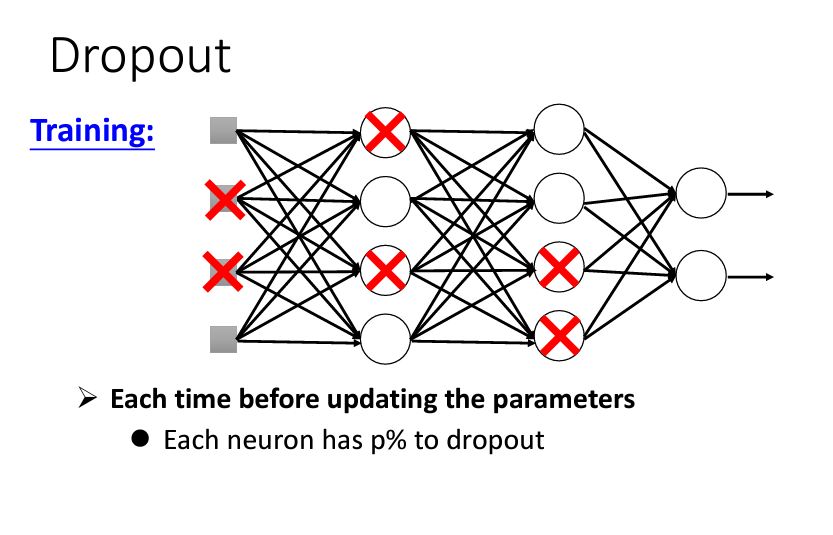
結構動態變化: 被丟棄的 neuron 及其相關的 weights 暫時失去作用,整個 network 結構變得「瘦長」。隨著每次抽樣重置,每次訓練所用的 network 結構都不同。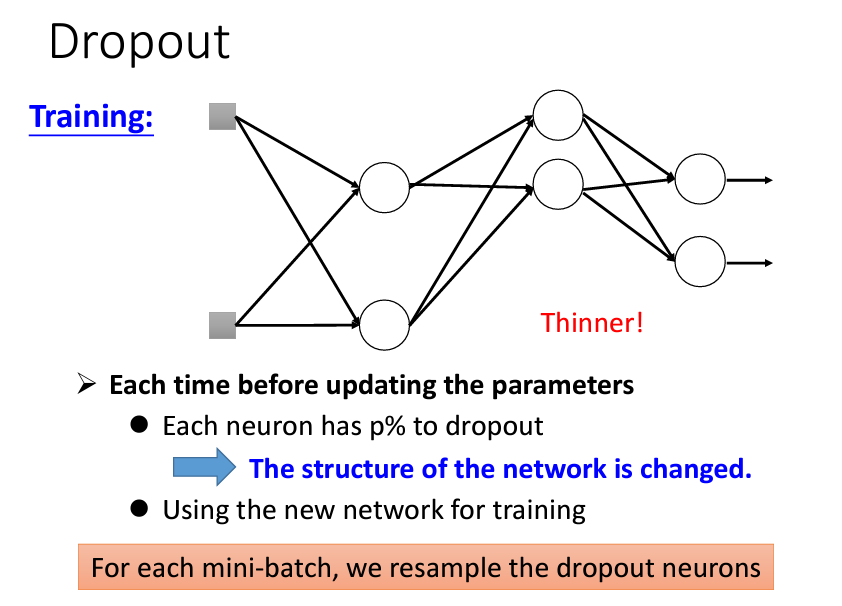
測試時取消 Dropout: 在測試階段,所有 neuron 均啟用,沒有 dropout。這樣才能充分利用所有 neuron 的作用,提高測試準確度。
調整 Weight: 假設在訓練期間的 dropout rate 為 ( p %) ),則在測試時將所有 weights 乘以 ( (1 - p) %) ),以補償訓練過程中丟棄的 neuron 對結果的影響。
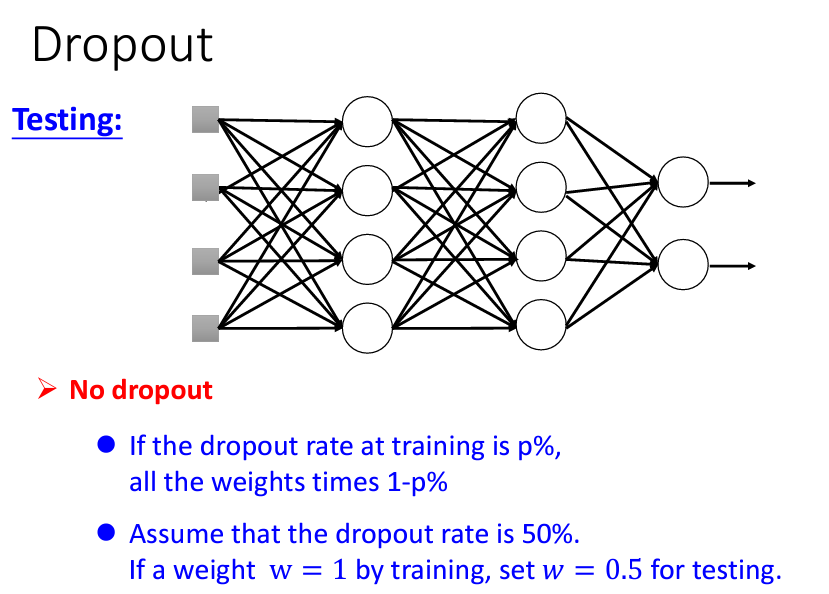
防止過擬合: Dropout 在訓練中隨機丟棄 neurons,使 network 必須在不完整的情況下學習,減少對特定 neuron 的過度依賴,避免過擬合現象。
Dropout的比喻:

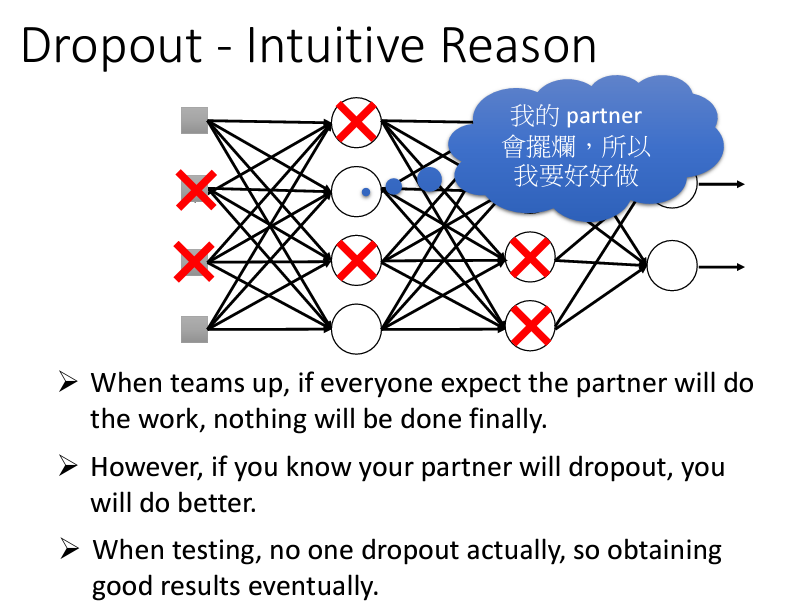
在訓練過程中使用 Dropout,可以讓模型學會更具彈性的特徵表示,從而減少過擬合。訓練完畢後,在測試階段則將所有神經元激活,通過加權平均的方式來保持模型穩定性。
以上的内容來自於臺大教授李宏毅:鏈接,我只是把他的影片寫成了筆記。

